
Комментарии участников:

Наверно, выражу общее мнение — заебали уже псевдо-новостями. Поисковик индексирует то, что находит и что ему позволяют индексировать. Еще раз сошлюсь на механизмы работы с поисковыми машинами — http://robotstxt.org.ru/. Все эти утечки персональных данных — вина разработчиков и администраторов ресурсов, на которые эти данные попадают от самих пользователей. Яндекс, кстати, как и Гугл и другие, отношения ко всему этому не имеют.
Новость — спам.
Новость — спам.

тут можно попенять только на вашу неосведомленность.
пример, для того, чтобы лучше разбираться в технологиях. =)
leprosorium.ru/robots.txt — таким он был всегда потому как сообщество закрытое.
а теперь смотрим выдачу
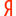 yandex.ru/yandsearch?serverurl=leprosorium.ru&lr=2
yandex.ru/yandsearch?serverurl=leprosorium.ru&lr=2
Собираем майлы пользователей с установленным яндекс баром. =))))
Для того чтобы не быть голословным цитата и сегодняшних пояснялок от яндекса:
Еще вопросы есть?
пример, для того, чтобы лучше разбираться в технологиях. =)
leprosorium.ru/robots.txt — таким он был всегда потому как сообщество закрытое.
а теперь смотрим выдачу
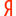 yandex.ru/yandsearch?serverurl=leprosorium.ru&lr=2
yandex.ru/yandsearch?serverurl=leprosorium.ru&lr=2Собираем майлы пользователей с установленным яндекс баром. =))))
Для того чтобы не быть голословным цитата и сегодняшних пояснялок от яндекса:
В браузер могут быть встроены и другие плагины. Например, Яндекс.Бар или Google.Бар показывают ранг страницы, для чего передают ее адрес на сервер.
Еще вопросы есть?
Отвечаю последний раз, простите, но времени копировать строчки с ресурса, на который я уже 10-й раз ссылаюсь, нет…
Файл robots.txt – это текстовый файл, находящийся в корневой директории сайта, в котором записываются специальные инструкции для поисковых роботов. Эти инструкции могут запрещать к индексации некоторые разделы или страницы на сайте, указывать на правильное «зеркалирование» домена, рекомендовать поисковому роботу соблюдать определенный временной интервал между скачиванием документов с сервера и т.д.http://robotstxt.org.ru/
простите вы бот?
По ссылкам ходить умеете?
Фаил роботс, даже правильно оформленный, ничего не запрещает (!) он лишь дает указание поисковым роботам по возможности не добавлять в индекс определенную информацию. Бот индексатор все равно пройдет по всем доступным страницам — программа у него такая.
Читайте логи серверов, если знаете, что это такое и посмотрите, что и откуда запрашивается ботами. =)
По ссылкам ходить умеете?
Фаил роботс, даже правильно оформленный, ничего не запрещает (!) он лишь дает указание поисковым роботам по возможности не добавлять в индекс определенную информацию. Бот индексатор все равно пройдет по всем доступным страницам — программа у него такая.
Читайте логи серверов, если знаете, что это такое и посмотрите, что и откуда запрашивается ботами. =)


а теперь смотрим выдачуЧто Вы хотели этим сказать?
yandex.ru/yandsearch?serverurl=leprosorium.ru&lr=2
Область поиска: сайт — leprosorium.ru
Искомая комбинация слов нигде не встречается.
ловить вчерашний день пришли?
 forum.searchengines.ru/forumdisplay.php?f=60
forum.searchengines.ru/forumdisplay.php?f=60
Сегодня с утра был апдейт и данные убраны.
 forum.searchengines.ru/forumdisplay.php?f=60
forum.searchengines.ru/forumdisplay.php?f=60Сегодня с утра был апдейт и данные убраны.
Вопрос не что он находит а как он находит. Эти данные можно получить только используя «следящее» ПО.
К тому же это прямое нарушение приватности, виноваты все
К тому же это прямое нарушение приватности, виноваты все
Этот ответ таков: файл robots.txt не предназначен для контроля доступа и не должен для него использоваться. Рассматривайте его не как замок на двери, а как табличку «не входить». Если доступ к определенным файлам на сервере нужно ограничить – используйте систему авторизации доступа. Поддержка Basic Authentication появилась в веб-серверах еще на заре веб (например, она очень просто настраивается на Apache), а если вам нужно что-то посерьезнее, используйте SSL.http://robotstxt.org.ru/chavo#robots.txt_
Следящее ПО, блять… Работать надо грамотно, просто… Не заставляйте материться… Меньше всего тому же Яндексу нужно это — индексировать какие-то пользовательские данные. А с теориями заговоров, идите к психологу. Все как всегда проще — никто ничего тайного не придумывал, просто посадили студента и он напипячил, а теперь Яндексу нужно объяснять, как так получилось, что где-то там студенту дали подработать…
Да какая разница?
К примеру это могло бы быть и так (а это, между прочим, прямо из ссылки, что я постил выше):
К примеру это могло бы быть и так (а это, между прочим, прямо из ссылки, что я постил выше):
Кто-то может разместить ссылку на ваши файлы на своем сайте. Или их названия могут появиться в общедоступном лог-файле, например, генерируемом прокси-сервером, через который ходят посетители вашего сайта. Или кто-то может перенастроить сервер, опять сказав ему отдавать список файлов в директории.Есть особенности реализации индексирования в разных системах. Тут много писали о всевозможных тулах. Но сути этого не меняет — это не поисковик ищет слишком хорошо, это ребята не дали понять поисковику, что ему стоит индексировать, а что нет.
Просто яндекс попал в некрасивую ситуацию — его сервисы работают как шпионское ПО, признавать они это не хотят, поэтому всеми силами перекладывают вину на владельцев веб сайтов.
Так, давайте по порядку. По вашему проблема не в том, что данные попали на индексацию, а в том, как именно их собрал поисковик?
По мойму виноваты оба как владельцы сайта так и яндекс. Только яндекс не хочет признавать пробему и сваливает все на владельцев веб сайтов.
В чем виноват Яндекс? И почему, только Яндекс?
И вы на вопрос не ответили, вас реально беспокоит не индексация пользовательских данных, а только методы сбора информации поисковиками?
И вы на вопрос не ответили, вас реально беспокоит не индексация пользовательских данных, а только методы сбора информации поисковиками?

ваще то яндексу должно было прийти в голову что паспортные данные буде таковые найдутся надо из базы выпиливать. может закон свежий на эту мысль натолкнет. посмотрим.
слишком много ньюансов с реализацией самой идеи и со смежными: типа, а если специально постили (потеряли паспорт), что делать с номерами страховки, и т.д. где ограничивать. + дело, как я уже говорил, не в Яндексе, то же надо применять ко всем поисковикам. А это выработка нового протокола-стандарта, причем общемирового. Причем по весьма аморфным критериям. Кажется, идея весьма бесперспективной.
это так кажется до первого хорошего суда ) Мегафон тоже не видел технической возможности траффик в роуминге билить ;)
Не, это сильно разные вещи. Я бы сказал, не сопоставимо разные. Тут с любой точки зрения — проблема в недоработке администраторов и разработчиков этих «проблемных» ресурсов.
идешь по дороге находишь паспорт. ксеришь его и развешиваешь по всем углам, ну работа у тебя такая — ксерить и объявы вешать…
потом по этому паспорту берут пару лямов кредита… соучастник ты или просто у тебя так робот работает? )
потом по этому паспорту берут пару лямов кредита… соучастник ты или просто у тебя так робот работает? )
Не буду дальше спорить, аналогия не корректна… Просто есть стандарт работы с поисковиками, и тут он нарушен. Не со стороны поисковика, а со стороны администраторов ресурса.
Если более верную аналогию придумать, это будет так: у вас есть окно, через которое вас видят. И вы знаете, что нужно не ходить голым перед этим окном. А тут вы вышли голым (по незнанию, как окно работает или просто забыли одеться) и случился конфуз. Глупо в это винить производителей окон, как вам кажется?
Если более верную аналогию придумать, это будет так: у вас есть окно, через которое вас видят. И вы знаете, что нужно не ходить голым перед этим окном. А тут вы вышли голым (по незнанию, как окно работает или просто забыли одеться) и случился конфуз. Глупо в это винить производителей окон, как вам кажется?
окна то тут особо не причем… а вот гугломобиль который как раз занимался «подглядыванием» — пару скандалов инициировал.
паспортные данные буде таковые найдутся надо из базы выпиливатьЯ думаю, если Вы научитесь хорошо и быстро определять (программно) наличие паспортных данных в документе, Вас позьмут работать в Яндекс.
