


Комментарии участников:

Поправки в вашу формулу ранжирования недавно пыталось внести и государство. Я имею в виду последние предложения Минкульта, от которых оно уже вроде бы отказалось. Такие пожелания поднимать в поисковой выдаче правильные с чьей-то точки зрения ресурсы вообще реализуемы?
Вообще не реализуемы. У нас же машинное обучение, оно, как зеркало, отражает именно то, что хотят найти пользователи. Мы фанаты машинного обучения, мы вообще никогда не вмешиваемся в поиск «вручную».
Если вы не вмешиваетесь в поиск и у вас есть такая замечательная автоматическая методика проверки качества поиска, то зачем вообще использовать ручные оценки асессоров?
На это есть по крайней мере две причины. Во-первых, люди врут. Они могут искать, скажем, реферат по истории, а переходить при этом на порносайты — это же интереснее. Во-вторых, врут авторы сайтов. Они могут создавать видимость того, что на сайте есть какой-то контент, а на самом деле его там нет. Ведь по сниппету, тому окошечку с фрагментом сайта, который выдает поисковая машина, понять, подходящий ли это сайт, не всегда возможно. Пользователь перешел на сайт, потратил там какое-то время. А нашел он там то, что нужно, или нет — мы не знаем и можем только об этом догадываться.
Еще одна важная проблема при оценке качества — редкие запросы, на которые нет статистики, так называемый длинный хвост. Их на самом деле очень много — из всех запросов около 30-40 процентов приходятся на те, что никто никогда еще не задавал. Поэтому без живых асессоров невозможно понять, насколько качественно работает поиск.
Асессоры оценивают странички выдачи поисковой машины или отдельные URL?
Ни то, ни другое — они оценивают пары запрос-URL, причем в запросе подшита информация о географии пользователя, и эта информация учитывается в оценке. Потому что, условно, релевантный для Екатеринбурга сайт по запросу «ресторан суши» будет нерелевантным для Новосибирска, и наоборот.
Чтобы измерить качество поиска, мы пропускаем случайную выборку запросов через асессоров, которые оценивают пары запрос-URL, выставляя им оценки: «витальный», «важный», «релевантный» или «нерелевантный». Каждой из оценок соответствует некая вероятность того, что человек найдет на этом сайте то, что ему нужно.
Что происходит после того, как асессоры оценили релевантность запроса-URL?
Имея ранжированную страницу с результатами поиска, где все URL оценены асессорами, мы оцениваем качество поиска с помощью специальной метрики pfound. Она вычисляет вероятность того, что человек нашел то, что искал на странице выдачи, суммируя такие вероятности для разных URL — каждой из четырех оценок асессора присвоена своя вероятность полезности. При этом в ходе суммирования мы учитываем, что вероятность полезности этой строки нужно умножать на вероятность того, что ее вообще прочитают. То, что нужно пользователю, может найтись в предыдущей строчке, кроме того, он может просто устать и прекратить чтение списка. В общем, получается такая формула суммирования вероятностей, которая и позволяет нам оценивать качество поиска — как своего, так и конкурентов.
Итак, с одной стороны, мы имеем метрику для оценки качества поиска, с другой стороны, имеем систему машинного обучения, которая пытается максимизировать эту метрику. Чем больше оцененных запросов мы будем направлять в «Матрикснет», тем лучше будет работать поиск.
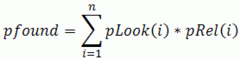 источник: icdn.lenta.ru
источник: icdn.lenta.ruЗдесь: pRel — релевантность i-того документа (вероятность того, что пользователь найдет ответ в этом документе). pLook — вероятность просмотра i-того документа в выдаче.
Формула pfound оценивает вероятность найти нужную информацию на странице выдачи поисковой машины, суммируя вероятности по отдельным URL.
Эта метрика, насколько я понимаю, специфична именно для конкретного запроса. А человек ведь не мыслит запросами, он мыслит задачами. Существуют ли способы измерить, нашел ли человек то, что искал, независимо от запроса?
На нашем сленге эта метрика называется «счастье пользователя». Да, такие опыты мы делаем. Выглядит это так: человеку ставят задачу, скажем, найти героев Куликовской битвы. Он может задавать любые запросы, переформулировать их, читать какую-то новую информацию, снова переформулировать запросы. В какой-то момент он находит то, что нужно, и записывает ответ. Мы со своей стороны пытаемся минимизировать то время, которое человек на это потратил.
Все эксперименты, которые мы проводили, говорят о том, что метрика счастья очень хорошо коррелирует с метрикой pfound. То есть пользователь, конечно, ведет себя сложнее, чем подразумевает модель pfound, но данных настолько много, что вся эта сложность усредняется.